
Transformer
Transformerは“Attention Is All You Need”という論文で提案されたモデルで、LSTM・CNNを愛用していた人たちに対する挑発的なタイトルでも話題になりました。CNNでもLSTMでもない dot product Attentionという機構で、それを積み重ねたモデル(Transformer)で既存手法を大きく上回る成果を上げています。
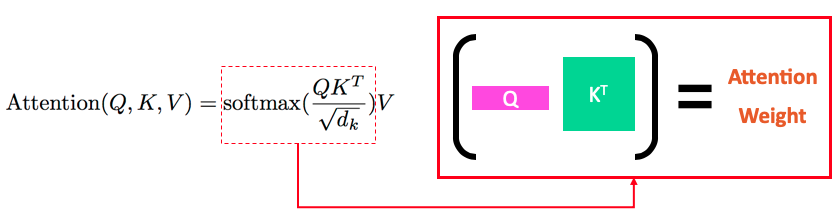
Transformerで使われる(dot-product) Attentionでは、Query, Key, Valueの3つの変数を使います。端的にいえば、Query単語とKey単語の関連性(Attention Weight)を計算し、それぞれのKeyに紐づくValueをかけるという仕組みです。
GPT-2
GPT-2は大規模なデータセットと表現力の高い大規模モデルを使って自己回帰型言語モデルを構築し、その言語モデルをそのまま使って様々なタスクを解く(zero-shot)研究です。「自己回帰モデルによるzero-shot」「大規模なモデル」「大規模なデータセット」の3要素で構成されています。GPT2の結果
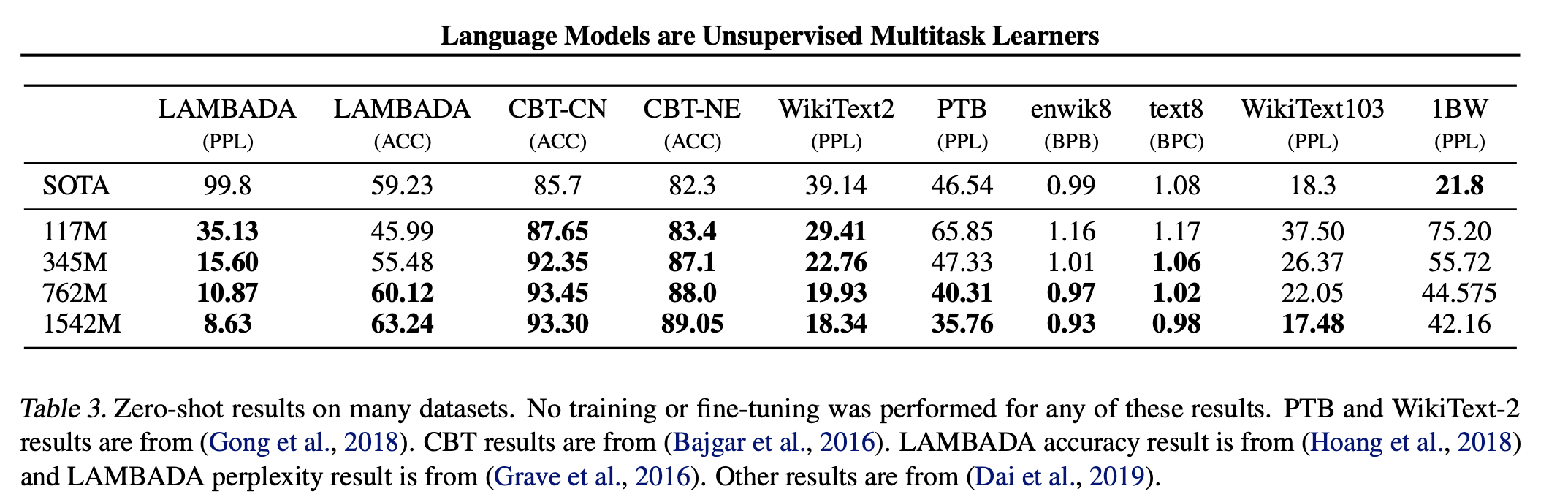
「自己回帰モデルによるzero-shot」「大規模なモデル」「大規模なデータセット」の3要素で構成されたGPT-2が叩き出した結果が下の表です。様々なデータセットでSOTAを更新しています。それぞれのデータセットでFine-tune学習どころかFew-shot学習さえしていないことに注意してください。GPT-2の論文のタイトル通り”Language Models are Unsupervised Multitask Learners”だということを示しています。
GPT-3
「自己回帰型言語モデルによるzero-shot」「大規模なモデル」「大規模なデータセット」3つの要素をもったGPT-2がとても強力なものだということは分かって頂けたかと思います。では、それらの3要素をさらに強化したらどうなるのでしょうか?
その3要素の強化を実施したのがGPT-3です。具体的にいうと下記のようになります。それぞれどういうことなのか詳しく見ていきます。
その3要素の強化を実施したのがGPT-3です。具体的にいうと下記のようになります。それぞれどういうことなのか詳しく見ていきます。
- 自己回帰型言語モデルによるzero-shot → 自己回帰型言語モデルによるFew-shot
- 大規模なモデル → さらに大規模なモデル
- 大規模なデータセット → さらに大規模なデータセット
自己回帰型言語モデルによるFew-shot
GPT-2では言語モデルを再学習せずにそのまま使用するzero-shotでタスクをこなしていきました。GPT-3では、モデル構造とパラメータはそのまま使いつつも、複数回サンプルを示すFew-shotでタスクをこなします。zero-shot, one-shot, few-shotを示したのが以下の図です。 zero-shot, one-shot, few-shotの概念図。
zero-shot, one-shot, few-shotの概念図。MAMLのようなFew-shot “Learning”と異なり、one-shot, few-shotどちらにおいても勾配を使ったモデル更新をしないことに注意してください。あくまで数個のサンプルを言語モデルに指し示すだけです。(GPT-2でも、zero-shotだけでなく、このようなFew-shotを機構的には行うこと自体は可能です)
一方、BERTのようにFine Tuningを使うモデルや、オリジナルのTransformerで翻訳をしようと思うと、基本的には英仏両方のペアデータセットが必要であることに注意してください。

Fine Tuneの概念図。英仏ペアを使った更新が必要
長くなってしまったので今日はここまで。
長くなってしまったので今日はここまで。

0 件のコメント:
コメントを投稿